Concepts de base
Introduction
L'estimation statistique vise à déterminer la valeur de paramètres inconnus à partir des données observées d'un échantillon [kay1993] [casella2002]. Pour déterminer la valeur des paramètres, les observations sont décrites à l'aide d'un modèle statistique, c'est-à-dire d'une loi de probabilité dépendant des paramètres d'intérêt. L'estimation consiste alors à exploiter conjointement les données et ce modèle paramétré afin de fournir une approximation des paramètres inconnus.
Dans ce chapitre, nous considérons en particulier un exemple très simple: l'estimation de la moyenne d'un échantillon issu d'une loi gaussienne.
Modèle statistique
Un modèle statistique est un ensemble de distributions de probabilité
Exemple : Loi normale (gaussienne)
Définition : Une variable aléatoire
Propriétés :
(moyenne ou espérance) (variance)
Visualisations :
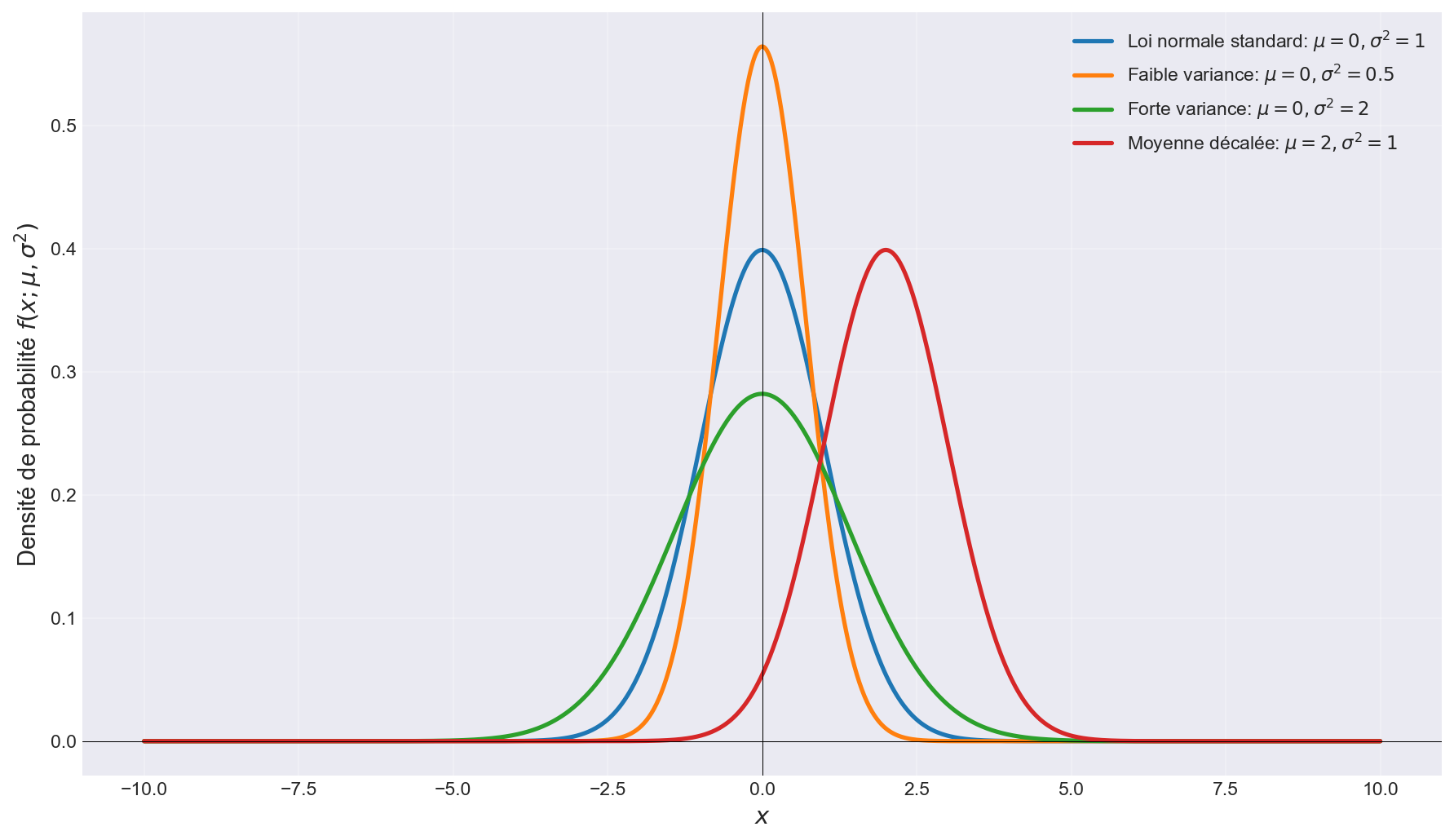
Figure 1: Loi normale avec différents paramètres μ et σ²
Soit
Estimateur
Un estimateur de
qui approxime le paramètre
Propriétés des estimateurs
Pour évaluer la qualité d'un estimateur, nous étudions plusieurs propriétés fondamentales. Ces propriétés permettent de comparer différents estimateurs et de choisir le plus approprié selon le contexte.
Biais
Le biais d'un estimateur
Un estimateur est dit sans biais si
Variance
La variance d'un estimateur
La variance quantifie la dispersion des estimations d'un échantillon à l'autre. Un estimateur peut être sans biais mais avoir une variance élevée (peu fiable), ou avoir un biais non nul mais une variance faible (précis mais biaisé).
Efficacité
Parmi les estimateurs sans biais, celui de variance minimale est dit efficace.
La borne de Cramér-Rao [cramer1946] établit une limite inférieure pour la variance de tout estimateur sans biais Kay (1993) : sous certaines conditions de régularité,
où
Convergence
Un estimateur est dit convergent s'il se rapproche du paramètre vrai lorsque la taille de l'échantillon augmente. Formellement,
On note :
Pour un échantillon suffisamment grand, la probabilité que l'estimateur soit éloigné de la vraie valeur devient arbitrairement petite. C'est une propriété asymptotique essentielle.
Erreur quadratique moyenne (EQM)
Le biais et la variance évaluent des aspects distincts de la qualité d'un estimateur. L'erreur quadratique moyenne (EQM ou MSE en anglais) est un critère global qui combine ces deux aspects :
Décomposition biais-variance : Cette quantité peut s'exprimer de manière remarquable comme :
L'EQM représente l'erreur moyenne au carré entre l'estimateur et la vraie valeur. Cette décomposition montre qu'il existe un compromis biais-variance :
- Un estimateur peut avoir un biais non nul mais une variance faible
- À l'inverse, un estimateur sans biais peut avoir une variance élevée
- L'objectif est de minimiser l'EQM totale, ce qui peut parfois justifier d'accepter un petit biais pour réduire significativement la variance
Intervalles de confiance
Les estimateurs ponctuels (comme
Un intervalle de confiance de niveau
Interprétation : Le nombre
Exemple : Estimation de la moyenne
Pour un échantillon
Propriétés :
- Sans biais :
, donc - Variance :
- Erreur quadratique moyenne :
- Convergence :
(loi des grands nombres)
Interprétation : L'EQM décroît en
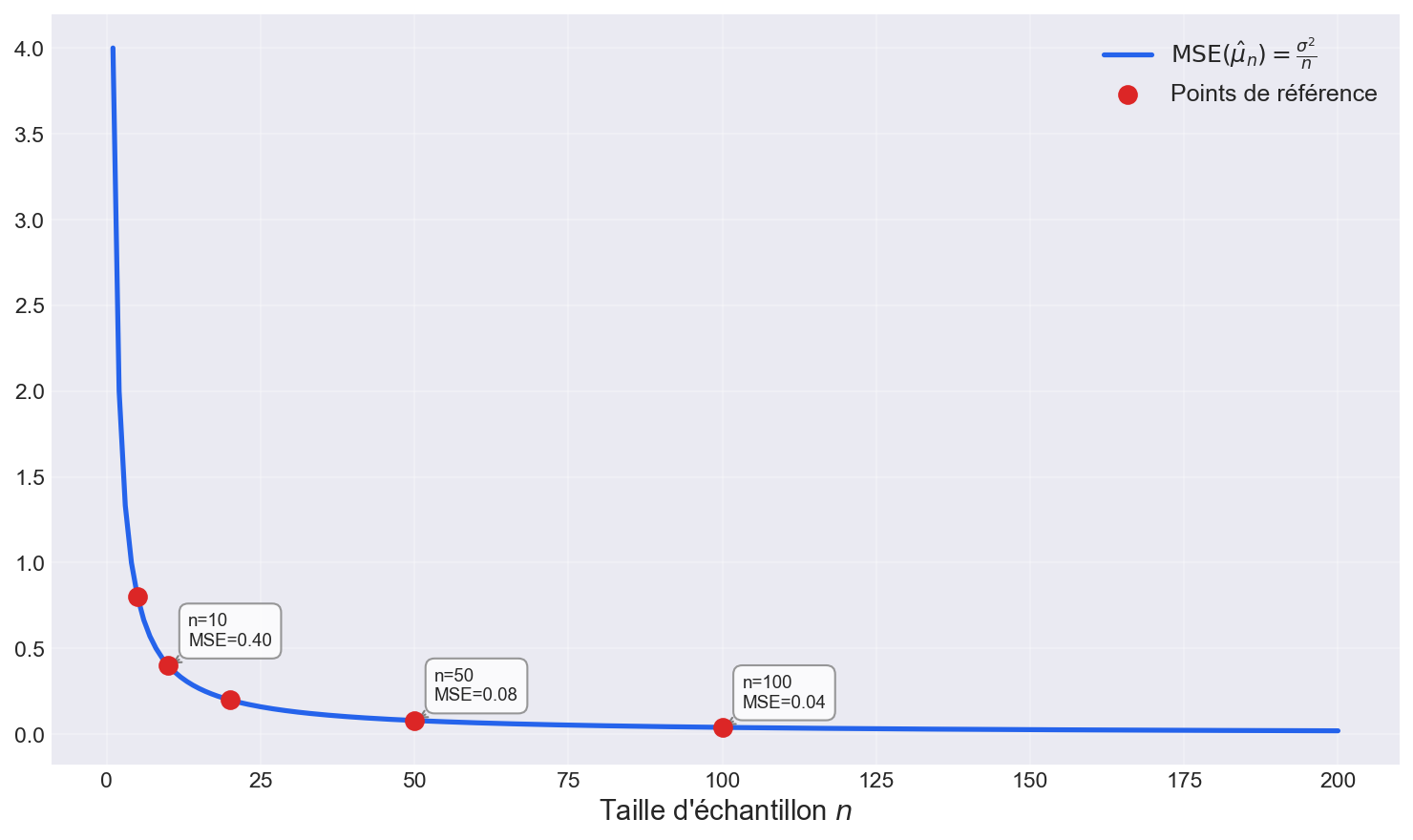
Figure 2: Évolution de l'erreur quadratique moyenne en fonction de la taille d'échantillon n
Références
- Kay, S. M. (1993). Fundamentals of Statistical Signal Processing: Estimation Theory. Prentice Hall.
- Lehmann, E. L., & Casella, G. (1998). Theory of Point Estimation, 2nd edition. Springer.
- Casella, G., & Berger, R. L. (2002). Statistical Inference, 2nd edition. Duxbury Press.
- Cramér, H. (1946). Mathematical Methods of Statistics. Princeton University Press.