Régression Linéaire - Fondements
Introduction
La régression linéaire est l'une des méthodes statistiques les plus fondamentales et les plus utilisées Kay (1993) [casella2002]. Elle permet de modéliser la relation entre une variable dépendante (ou variable à expliquer) et une ou plusieurs variables indépendantes (ou variables explicatives). Nous avons vu au Chapitre 2 que sous l'hypothèse de bruit gaussien, l'estimateur du maximum de vraisemblance coïncide avec l'estimateur des moindres carrés. Dans ce chapitre, nous approfondissons l'étude de ce modèle en analysant ses propriétés, ses applications et ses extensions.
Modèle de régression linéaire
Formulation générale
Considérons un ensemble de
où :
est le vecteur des observations (variable dépendante) est la matrice de design (variables explicatives) est le vecteur des paramètres (coefficients de régression) est le vecteur des erreurs (bruit gaussien)
Hypothèses du modèle :
- Linéarité : La relation entre
et est linéaire en - Indépendance : Les erreurs
sont indépendantes - Homoscédasticité : Les erreurs ont toutes la même variance
- Normalité : Les erreurs suivent une loi normale
- Non-colinéarité : Les colonnes de
sont linéairement indépendantes (rang plein)
Interprétation des composantes
Pour chaque observation
où
Estimateur des moindres carrés
Dérivation
L'estimateur des moindres carrés ordinaires (Ordinary Least Squares, OLS) minimise la somme des carrés des résidus :
En développant le critère et en annulant le gradient, nous obtenons les équations normales :
Si
où
Interprétation géométrique
L'estimateur OLS projette orthogonalement le vecteur des observations
où
Le vecteur des résidus est :
Propriété remarquable : Les résidus sont orthogonaux aux valeurs ajustées :
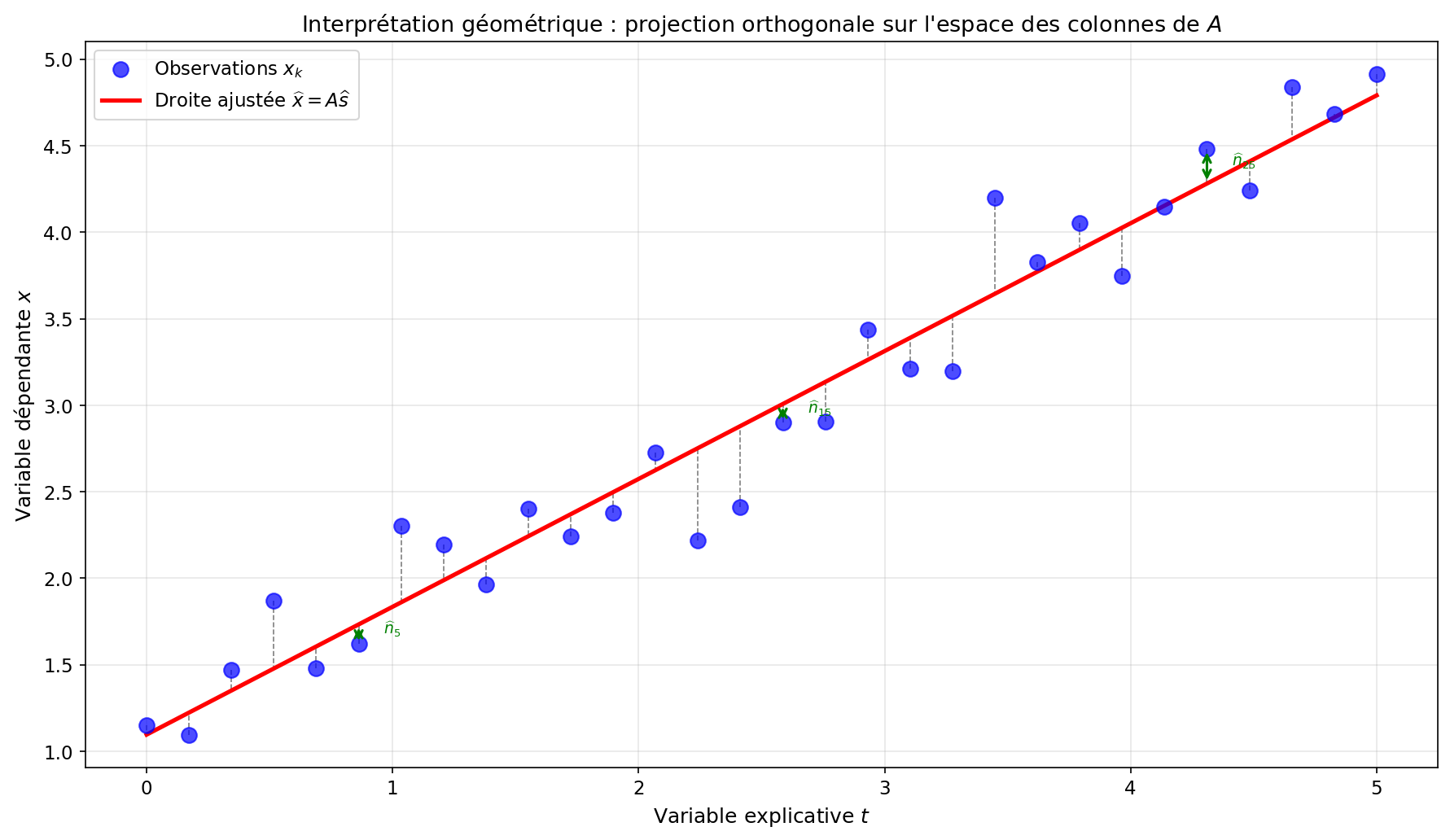
Figure 1: Interprétation géométrique de l'estimateur OLS comme projection orthogonale
Propriétés de l'estimateur OLS
Sans biais
L'estimateur OLS est sans biais :
Puisque
Matrice de covariance
La matrice de covariance de l'estimateur OLS est :
Démonstration :
Conséquence : La variance du
Théorème de Gauss-Markov
Le théorème de Gauss-Markov Casella (2002) établit que, parmi tous les estimateurs linéaires et sans biais, l'estimateur OLS a la variance minimale.
Énoncé : Soit
où
En d'autres termes, l'estimateur OLS est BLUE (Best Linear Unbiased Estimator) : le meilleur estimateur linéaire sans biais.
Remarque importante
Le théorème de Gauss-Markov ne nécessite pas l'hypothèse de normalité des erreurs. Il suffit que les erreurs soient non corrélées et de variance constante.
Loi de l'estimateur
Sous l'hypothèse de normalité des erreurs
Par conséquent, chaque coefficient
Estimation de la variance des erreurs
Estimateur non biaisé de
La variance des erreurs
où
Propriété : Cet estimateur est sans biais :
Somme des carrés et décomposition
La somme totale des carrés peut se décomposer :
où
Coefficient de détermination
Définition
Le coefficient de détermination
Interprétation :
: Le modèle explique parfaitement les données (ajustement parfait) : Le modèle n'explique aucune variance (pas mieux qu'une simple moyenne) : Le modèle explique partiellement les données
Coefficient de détermination ajusté
Le
Cette version corrige le fait que
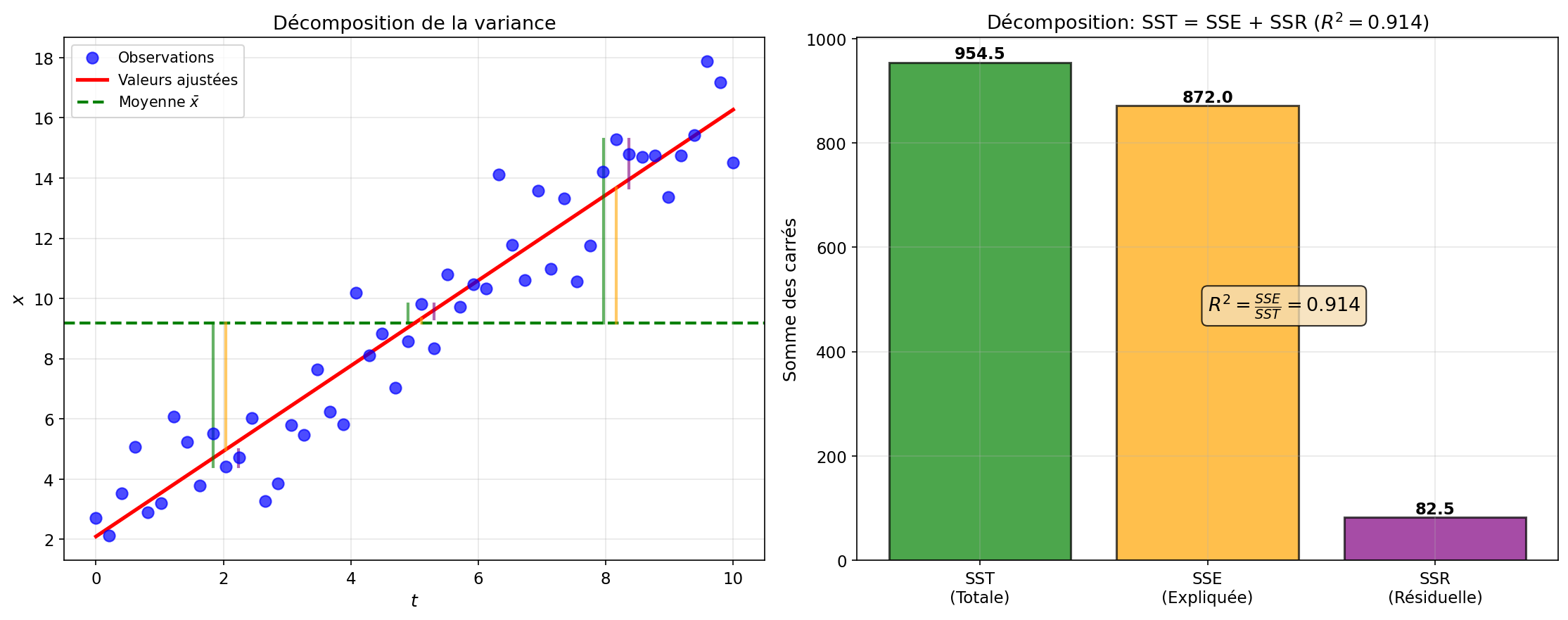
Figure 2: Décomposition de la variance et interprétation du R²
Références
- Kay, S. M. (1993). Fundamentals of Statistical Signal Processing: Estimation Theory. Prentice Hall.
- Casella, G., & Berger, R. L. (2002). Statistical Inference, 2nd edition. Duxbury Press.
- Wasserman, L. (2004). All of Statistics: A Concise Course in Statistical Inference. Springer.