Régularisation en Régression Linéaire
Introduction
Dans le Chapitre 4, nous avons étudié l'estimateur des moindres carrés ordinaires (OLS) pour la régression linéaire. Bien que l'OLS possède d'excellentes propriétés théoriques (BLUE, sans biais), il présente des limitations pratiques importantes :
- Surapprentissage : Lorsque le nombre de variables
est grand par rapport au nombre d'observations , l'OLS peut ajuster parfaitement les données d'entraînement mais mal généraliser - Instabilité : Quand les variables sont corrélées (multicolinéarité), les coefficients estimés deviennent instables
- Variance élevée : Pour
proche de , la variance des estimateurs explose
La régularisation est une famille de techniques qui ajoutent une pénalité au critère des moindres carrés pour contrôler la complexité du modèle et améliorer ses performances de généralisation.
Problème général de régularisation
Au lieu de minimiser simplement la somme des carrés des résidus, nous minimisons :
où :
est le terme d'attache aux données (fidélité) est le terme de régularisation (pénalité) est le paramètre de régularisation qui contrôle le compromis
Interprétation : La régularisation favorise les solutions qui :
- Ajustent bien les données (premier terme)
- Respectent certaines contraintes de simplicité (second terme)
Compromis biais-variance
Décomposition
L'erreur de prédiction d'un modèle se décompose en trois termes :
où :
- Biais : Écart systématique entre les prédictions moyennes et les vraies valeurs
- Variance : Sensibilité du modèle aux variations dans les données d'entraînement
- Bruit irréductible : Variance du bruit
Compromis
- Modèle simple (forte régularisation) : Biais élevé, variance faible
- Modèle complexe (faible régularisation) : Biais faible, variance élevée
- Objectif : Trouver le bon équilibre pour minimiser l'erreur totale
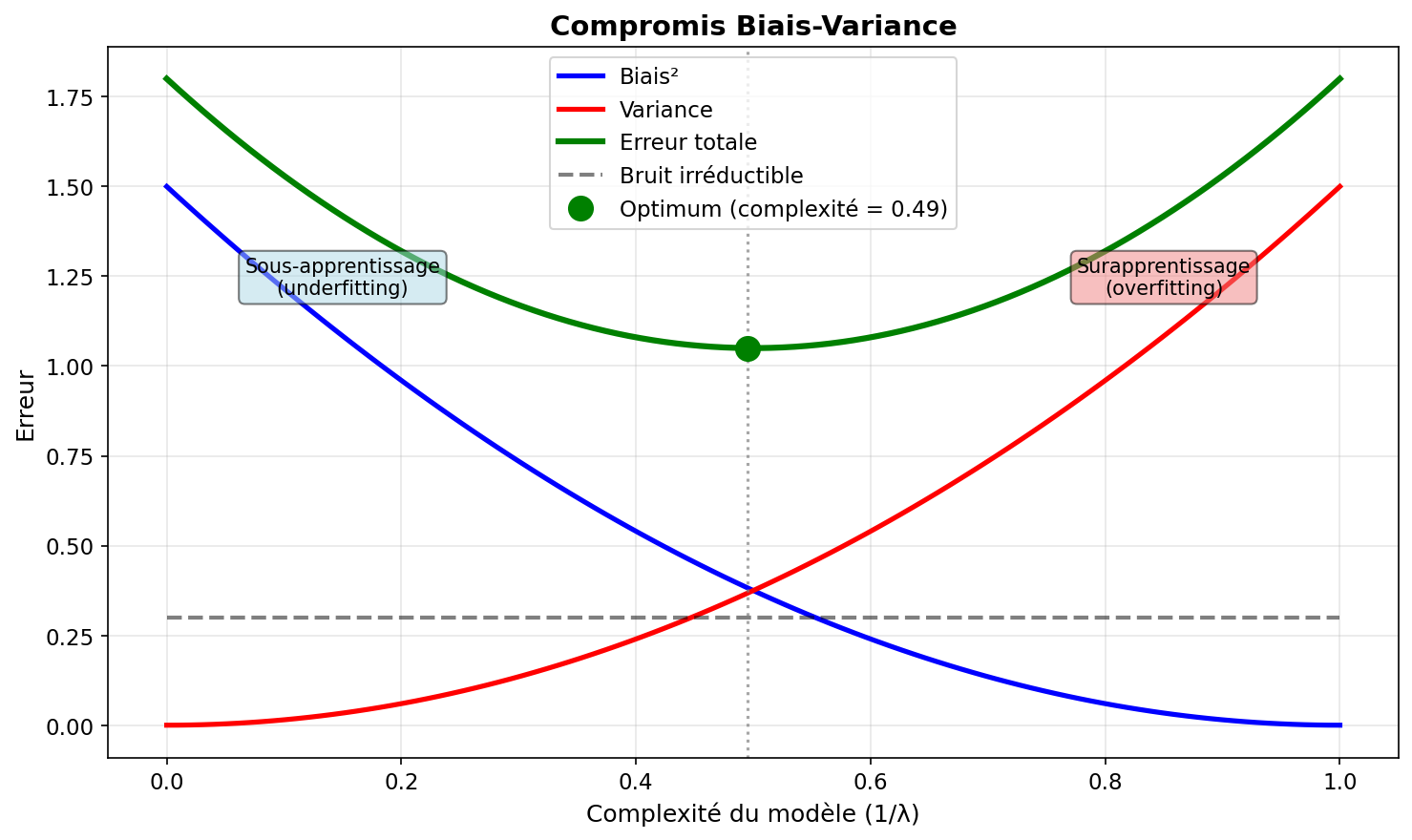
Figure 1: Compromis biais-variance en fonction de la complexité du modèle
Intuition
La régularisation augmente légèrement le biais mais réduit fortement la variance, ce qui améliore les performances de généralisation.
Régularisation L2 (Ridge)
Définition
La régression ridge ajoute une pénalité sur la norme L2 des coefficients :
avec
Effet : Pénalise les coefficients de grande amplitude, favorisant des solutions avec des coefficients plus petits et plus stables.
Solution analytique
La régression ridge admet une solution explicite :
Remarques :
- Pour
: on retrouve l'OLS - Pour
: la matrice est toujours inversible (même si ne l'est pas) - Le terme
stabilise l'inversion en ajoutant une valeur sur la diagonale
Interprétation bayésienne
Comme vu au Chapitre 3, la régression ridge correspond à un estimateur MAP avec une loi a priori gaussienne :
avec
Propriétés
- Réduction de la variance : Ridge diminue la variance des estimateurs au prix d'un léger biais
- Stabilité : Les coefficients sont plus stables face à de petites perturbations des données
- Pas de sélection de variables : Ridge ne met jamais de coefficients exactement à zéro
- Coefficients groupés : Les variables corrélées tendent à avoir des coefficients similaires
Chemin de régularisation
L'évolution des coefficients
: coefficients OLS (potentiellement grands) : tous les coefficients tendent vers zéro - Trajectoires continues et monotones
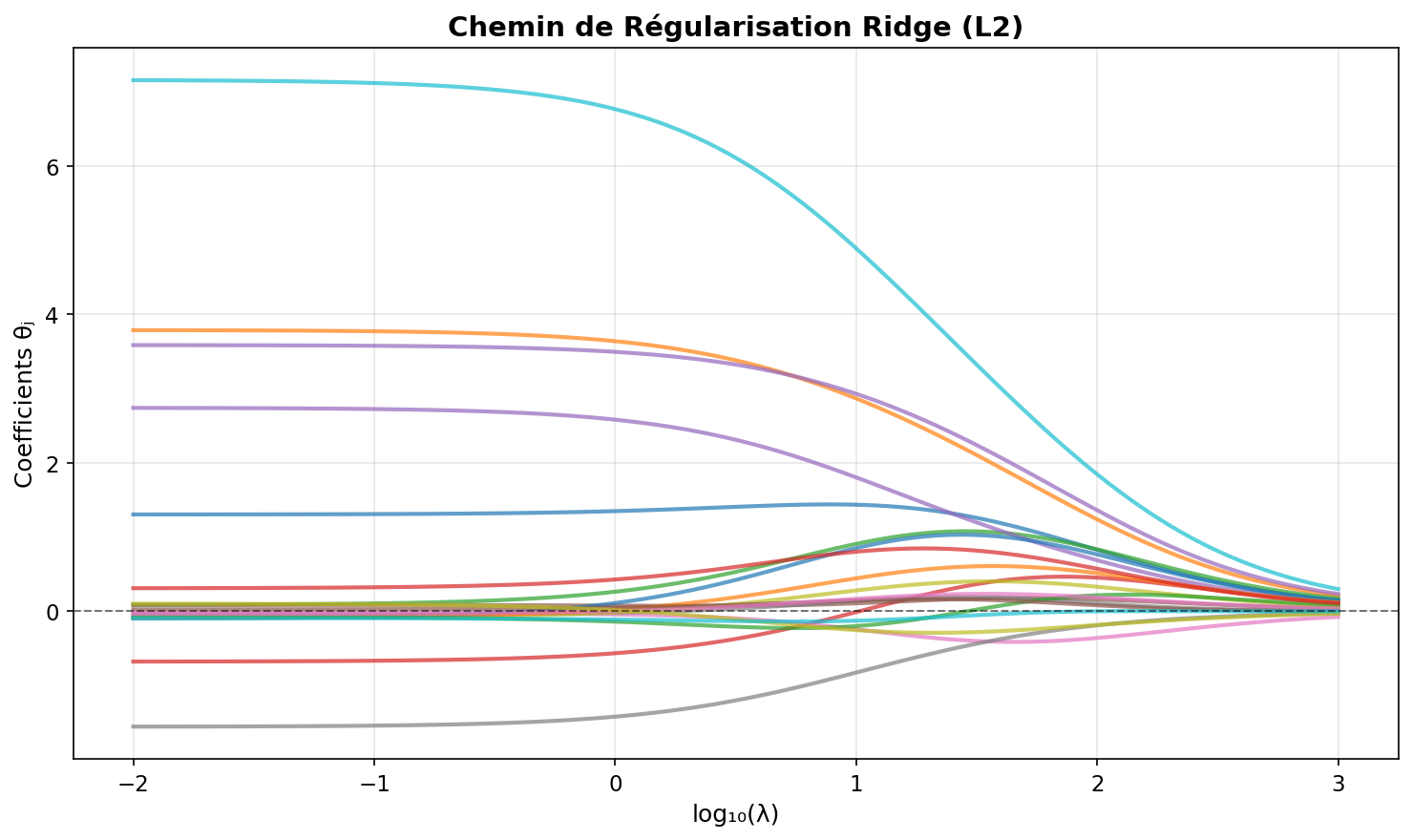
Figure 2: Trajectoire des coefficients ridge en fonction de log(λ)
Régularisation L1 (LASSO)
Définition
Le LASSO (Least Absolute Shrinkage and Selection Operator) utilise une pénalité L1 :
avec
Effet : Met certains coefficients exactement à zéro, réalisant ainsi une sélection automatique de variables.
Pas de solution analytique
Contrairement à ridge, le LASSO n'a pas de solution explicite en raison de la non-différentiabilité de
- Coordinate descent : optimise séquentiellement chaque coefficient
- LARS (Least Angle Regression) : construit le chemin de régularisation efficacement
- Proximal gradient : méthodes d'optimisation convexe avec opérateur proximal
Interprétation bayésienne
Le LASSO correspond à un estimateur MAP avec une loi a priori de Laplace (double exponentielle) :
Cette loi a des queues plus lourdes que la gaussienne, favorisant des coefficients nuls ou grands (sparse).
Propriétés
- Sélection de variables : Met automatiquement certains coefficients à zéro
- Parcimonie : Produit des modèles parcimonieux (sparse) avec peu de variables actives
- Instabilité de sélection : En présence de variables corrélées, LASSO peut arbitrairement en choisir une
- Limitation
: LASSO sélectionne au maximum variables (pas plus que d'observations)
Chemin de régularisation
Pour LASSO :
: solution OLS (si ) croissant : coefficients mis progressivement à zéro - Trajectoires linéaires par morceaux avec des points de rupture où des variables entrent/sortent
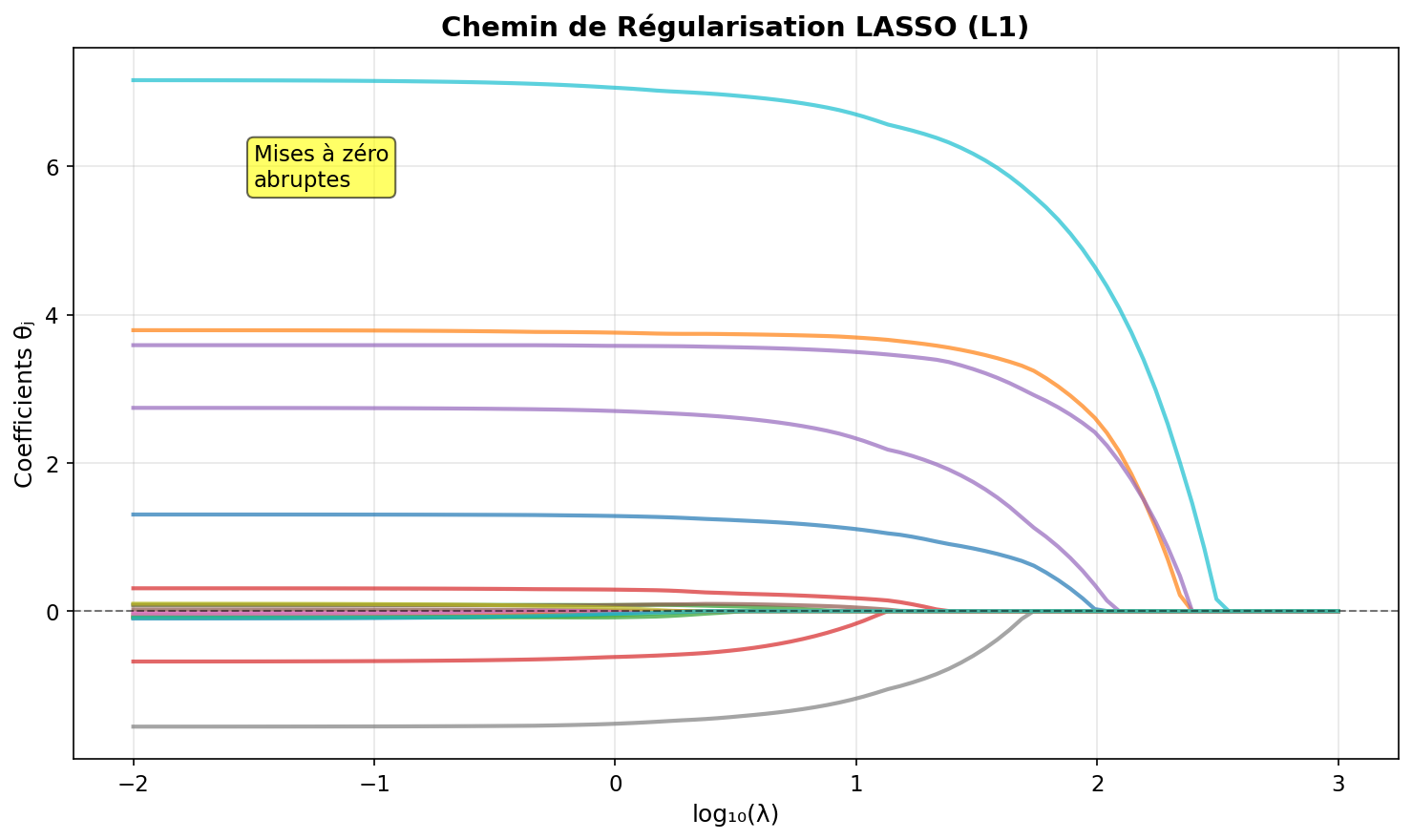
Figure 3: Trajectoire des coefficients LASSO - notez les mises à zéro abruptes
Soft-thresholding
L'opérateur de mise à jour pour coordinate descent est le soft-thresholding :
où
Régularisation L0
Définition
La régularisation L0 pénalise le nombre de coefficients non nuls :
avec
Objectif : Trouver le sous-ensemble optimal de variables qui minimise l'erreur.
Problème NP-difficile
La régularisation L0 est un problème combinatoire NP-difficile :
- Il faut tester toutes les combinaisons de variables (il y en a
) - Infaisable pour
grand (typiquement )
Algorithmes approchés
1. Recherche exhaustive
Pour
et choisir celui qui minimise l'erreur (critère AIC, BIC, validation croisée).
2. Forward selection (sélection séquentielle avant)
Algorithme glouton :
- Commencer avec un modèle vide
- À chaque étape, ajouter la variable qui améliore le plus le critère
- Arrêter selon un critère (AIC, BIC, validation)
Complexité :
3. Backward elimination (élimination séquentielle arrière)
Algorithme glouton :
- Commencer avec toutes les variables
- À chaque étape, retirer la variable qui dégrade le moins le critère
- Arrêter selon un critère
4. Stepwise selection
Combinaison de forward et backward : à chaque étape, on peut ajouter ou retirer une variable.
Critères de sélection
Pour choisir le nombre de variables, on utilise des critères qui pénalisent la complexité :
AIC (Akaike Information Criterion)
où RSS est la somme des carrés des résidus et
BIC (Bayesian Information Criterion)
Différence : BIC pénalise plus fortement la complexité que AIC (
Relaxation convexe : du L0 au L1
La norme L0 est non convexe (discontinue). LASSO est la relaxation convexe la plus proche :
Pour
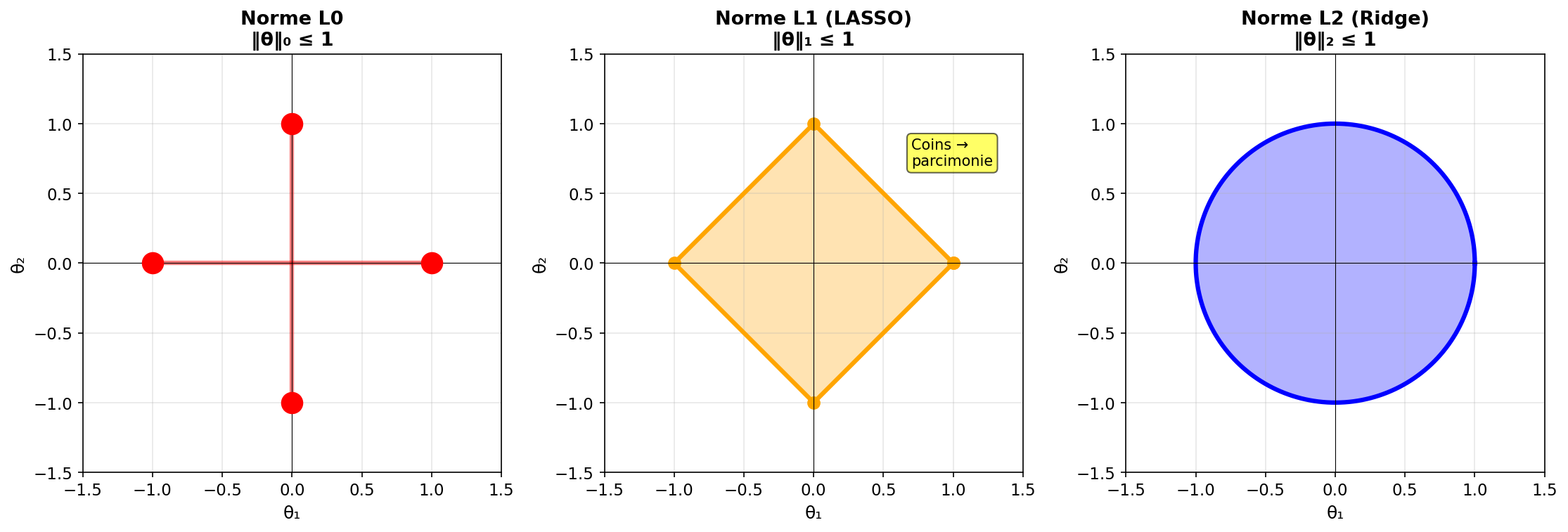
Figure 4: Boules unités pour les normes L0, L1, L2
Elastic Net
Définition
Elastic Net combine les pénalités L1 et L2 :
Souvent reparamétrisé avec un paramètre de mélange
avec :
: LASSO pur : Ridge pur : combinaison
Motivation
Elastic Net hérite des avantages des deux méthodes :
- Sélection de variables (grâce à L1)
- Stabilité et groupement (grâce à L2)
Particulièrement utile quand :
: LASSO est limité à variables, Elastic Net non - Variables corrélées : LASSO en choisit arbitrairement une, Elastic Net les groupe
Propriété de groupement
Quand deux variables
Cette propriété est absente de LASSO.
Validation croisée et choix de λ
Problème
Comment choisir le paramètre de régularisation
Objectif : Minimiser l'erreur de généralisation (pas l'erreur d'entraînement).
Validation croisée k-fold
Procédure :
- Diviser les données en
plis (folds) de taille égale - Pour chaque valeur de
candidate : - Pour chaque pli
: - Entraîner le modèle sur
plis - Prédire sur le pli
restant - Calculer l'erreur
- Entraîner le modèle sur
- Calculer l'erreur moyenne :
- Pour chaque pli
- Choisir
Valeurs typiques :
Règle du "one standard error"
Plutôt que de choisir le
où SE est l'erreur standard de l'erreur CV.
Avantage : Modèle plus parcimonieux (moins de variables) avec une erreur similaire.
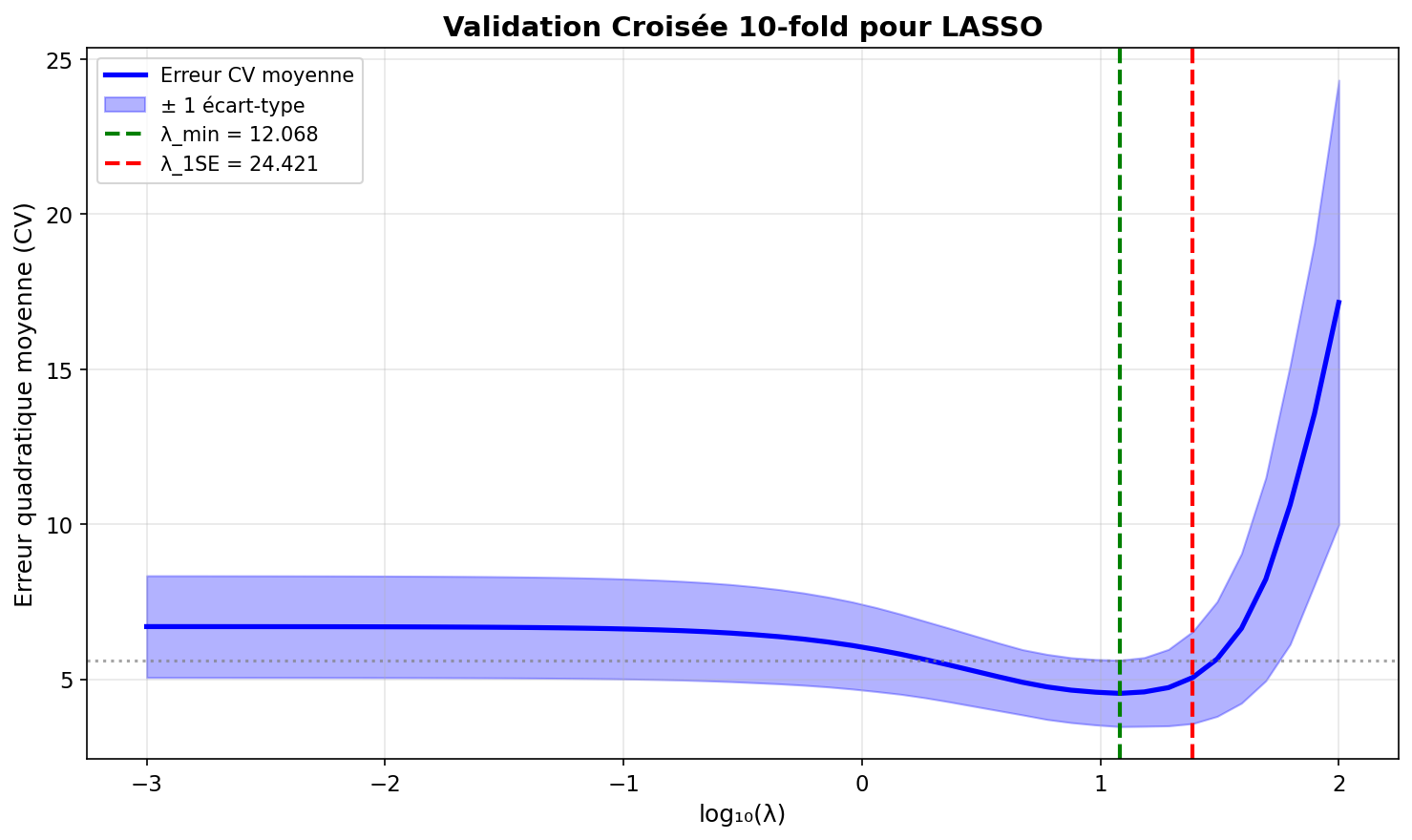
Figure 5: Erreur CV en fonction de log(λ) avec intervalles de confiance
Comparaison des méthodes
| Méthode | Sélection | Groupement | Solution | Convexe | |
|---|---|---|---|---|---|
| OLS | Non | Oui | Analytique | Oui | Non |
| Ridge (L2) | Non | Oui | Analytique | Oui | Oui |
| LASSO (L1) | Oui | Non | Numérique | Oui | Limité |
| Elastic Net | Oui | Oui | Numérique | Oui | Oui |
| L0 | Oui | - | NP-dur | Non | Oui |
Guide pratique
Utiliser Ridge quand :
- Toutes les variables sont potentiellement pertinentes
- On veut stabiliser les coefficients (multicolinéarité)
- On a besoin d'une solution analytique rapide
Utiliser LASSO quand :
- On veut sélectionner automatiquement des variables
- On suspecte que seules quelques variables sont importantes
- On veut un modèle interprétable (parcimonieux)
Utiliser Elastic Net quand :
- On veut sélectionner des variables ET gérer la corrélation
(plus de variables que d'observations) - On a des groupes de variables corrélées
Utiliser L0 (greedy) quand :
est petit ( ) - On veut exactement
variables - On peut se permettre le coût computationnel
Implémentation pratique
Normalisation des variables
Crucial : Avant d'appliquer ridge ou LASSO, normaliser les variables :
Raison : La pénalité doit être invariante à l'échelle des variables. Sans normalisation, une variable mesurée en km serait pénalisée différemment que la même mesurée en m.
Grille de λ
Tester une grille logarithmique :
avec typiquement
Pour LASSO :
Warm start
Pour calculer le chemin de régularisation, utiliser le warm start :
- Initialiser avec la solution pour
lors de l'optimisation pour - Accélère considérablement le calcul (10-100×)
Exemple numérique
Données synthétiques
Générons des données avec :
observations variables - Seulement 10 variables vraiment actives
- Corrélation entre certaines variables
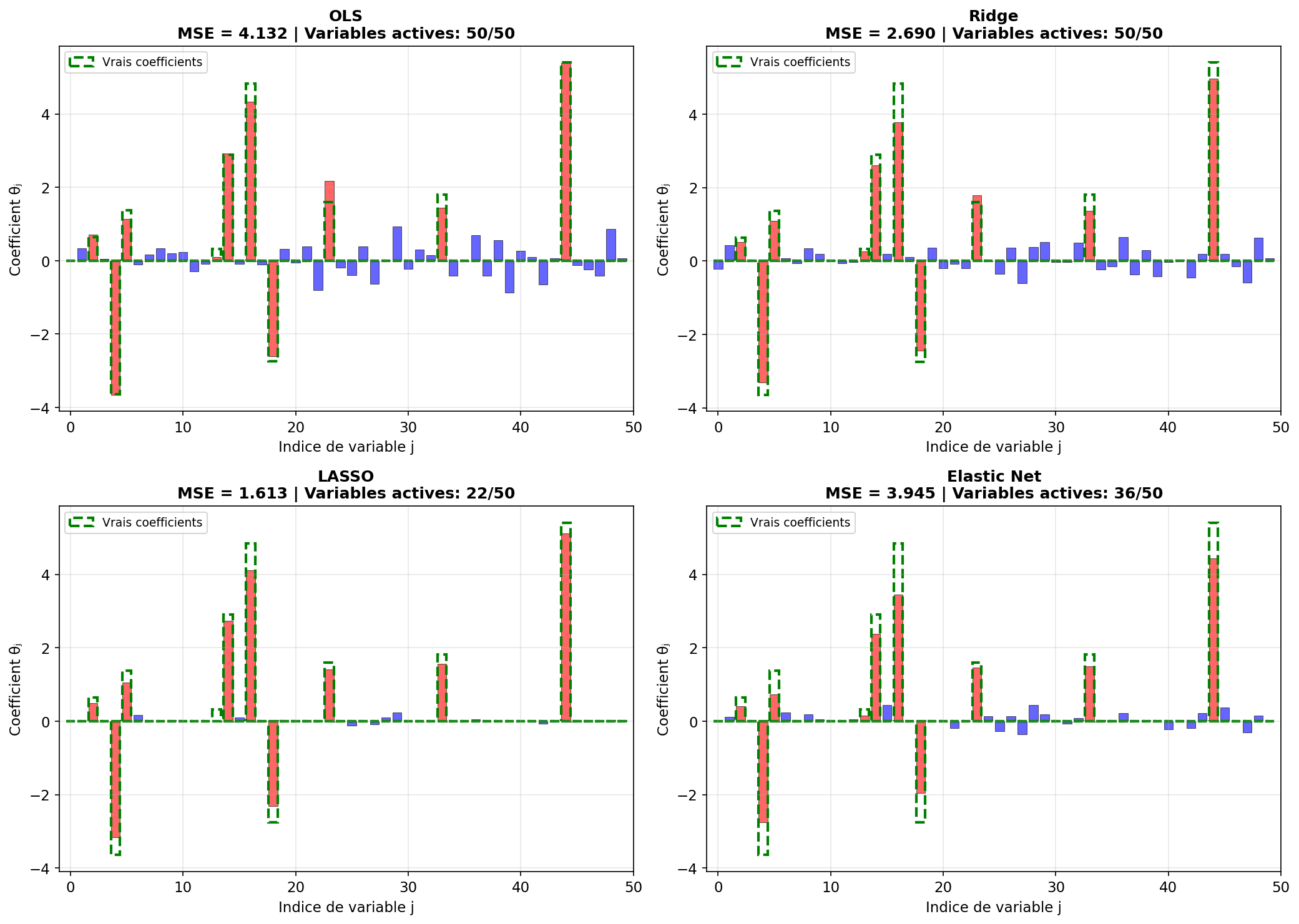
Figure 6: Comparaison Ridge, LASSO, Elastic Net sur données synthétiques
Résultats :
- Ridge : tous les coefficients non nuls mais petits
- LASSO : 12 coefficients non nuls (sélection correcte + 2 faux positifs)
- Elastic Net : 11 coefficients non nuls, meilleur compromis