Régression Linéaire - Inférence et Diagnostic
Introduction
Dans le Chapitre 4, nous avons étudié le modèle de régression linéaire, l'estimateur des moindres carrés (OLS) et ses propriétés fondamentales. Le Chapitre 5 a présenté les techniques de régularisation (Ridge, LASSO, Elastic Net) pour traiter les problèmes de surapprentissage et de multicolinéarité.
Dans ce chapitre, nous approfondissons l'inférence statistique et le diagnostic pour la régression linéaire :
- Construction d'intervalles de confiance pour les coefficients
- Tests d'hypothèses (tests individuels et test global)
- Diagnostic des résidus pour vérifier les hypothèses du modèle
- Problèmes courants (multicolinéarité, hétéroscédasticité, points aberrants) et leurs solutions
- Extensions du modèle OLS (ridge, LASSO, moindres carrés pondérés)
Intervalles de confiance et tests d'hypothèses
Intervalle de confiance pour un coefficient
Pour construire un intervalle de confiance pour
suit une loi de Student à
Un intervalle de confiance de niveau
où
Interprétation : Nous sommes confiants à
Test de significativité d'un coefficient
Pour tester l'hypothèse nulle
Calculer la statistique de test :
Comparer
à Rejeter
si (coefficient significativement différent de 0)
La p-valeur associée est :
Interprétation : La p-valeur représente la probabilité d'observer une valeur aussi extrême (ou plus) sous l'hypothèse nulle. Si
Test global du modèle (test de Fisher)
Pour tester si au moins une variable explicative a un effet, nous testons :
La statistique de test de Fisher est :
sous
Rejeter
Interprétation : Ce test permet de vérifier si le modèle dans son ensemble apporte une information significative par rapport à un modèle réduit à la seule moyenne.
Remarque
Le test de Fisher est un test global : il teste si au moins un coefficient est non nul. Les tests t individuels testent la significativité de chaque coefficient séparément.
Analyse des résidus
Importance des résidus
L'analyse des résidus
- Normalité : Les résidus doivent suivre une loi normale
- Homoscédasticité : La variance des résidus doit être constante
- Indépendance : Les résidus ne doivent pas présenter de corrélation
- Linéarité : Pas de tendance systématique dans les résidus
Si ces hypothèses ne sont pas respectées, les intervalles de confiance et les tests peuvent être invalides, même si l'estimateur OLS reste sans biais (sous certaines conditions).
Graphiques de diagnostic
Graphique 1: Résidus vs valeurs ajustées
Ce graphique permet de détecter :
- Hétéroscédasticité : Si les résidus forment une forme d'entonnoir (variance croissante ou décroissante)
- Non-linéarité : Si les résidus montrent une tendance systématique (parabole, etc.)
Comportement attendu : Les résidus doivent être dispersés aléatoirement autour de zéro, sans structure apparente.
Graphique 2: Q-Q plot (Quantile-Quantile)
Compare la distribution des résidus à une loi normale théorique pour vérifier la normalité.
Comportement attendu : Les points doivent être approximativement alignés sur la bissectrice.
Graphique 3: Scale-Location
Affiche
Comportement attendu : Ligne horizontale, indiquant une variance constante (homoscédasticité).
Graphique 4: Résidus vs Leverage
Identifie les points influents qui ont un fort impact sur l'estimation (leverage élevé et résidus importants).
Comportement attendu : Pas de points avec à la fois un leverage élevé et un résidu important (distance de Cook élevée).
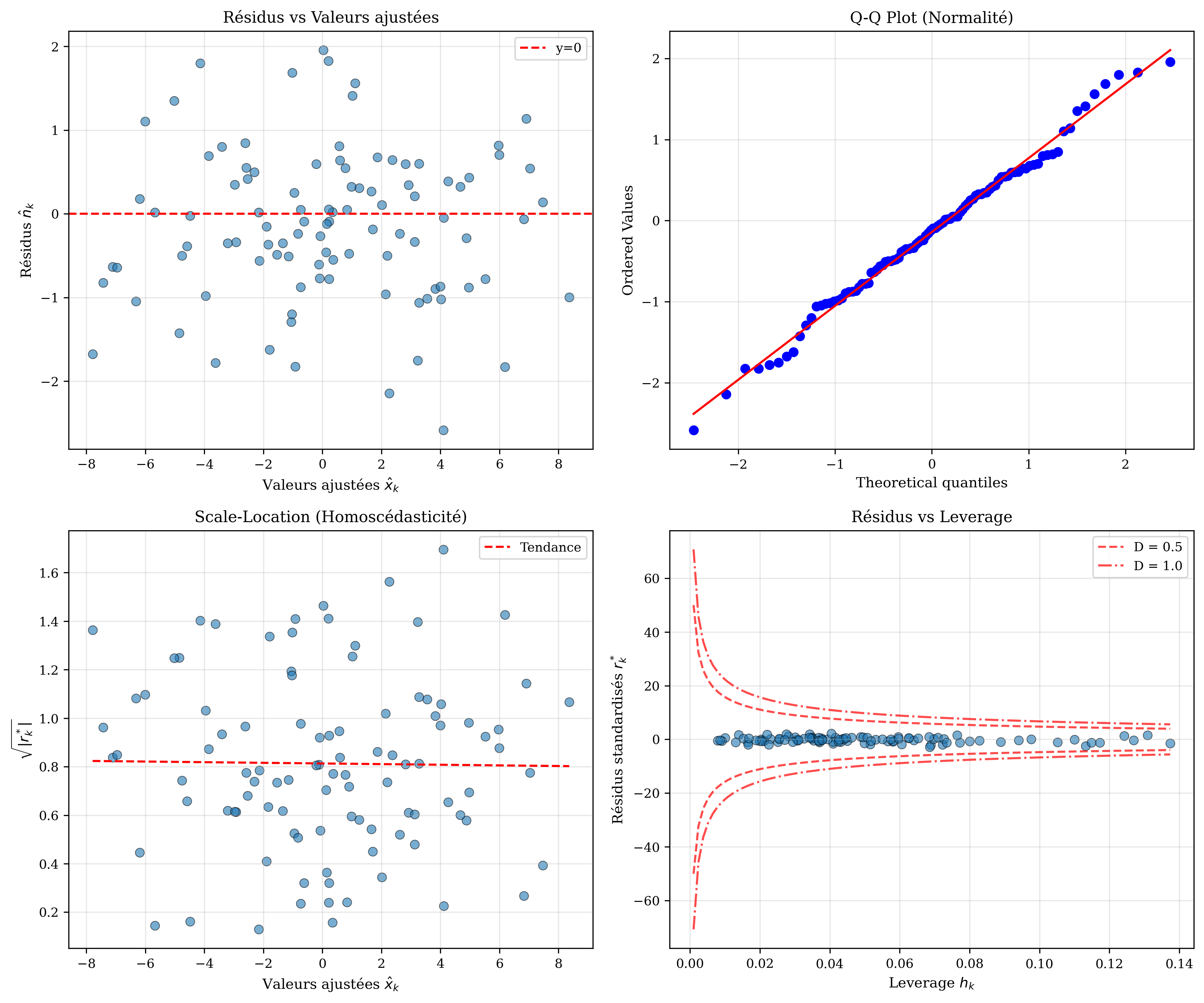
Figure 1: Graphiques de diagnostic pour l'analyse des résidus
Résidus standardisés
Les résidus standardisés permettent de comparer les résidus sur une échelle commune :
où
Interprétation : Un résidu standardisé
Problèmes courants et solutions
Multicolinéarité
La multicolinéarité survient lorsque certaines variables explicatives sont fortement corrélées entre elles.
Conséquences :
- La matrice
devient mal conditionnée - Les variances des estimateurs deviennent très élevées :
- Les coefficients deviennent instables (petites variations dans les données entraînent de grandes variations dans les estimations)
- Les intervalles de confiance deviennent très larges
- Les tests de significativité perdent en puissance
Détection :
Matrice de corrélation : Examiner les corrélations entre variables explicatives. Une corrélation
est problématique. Facteur d'inflation de la variance (VIF) :
où
est le de la régression de la -ième variable sur toutes les autres. : Pas de problème : Multicolinéarité modérée : Multicolinéarité sévère
Conditionnement de
: Si , la matrice est mal conditionnée.
Solutions :
Supprimer une des variables corrélées : Identifier les paires de variables fortement corrélées et en retirer une.
Régression ridge : Voir section Extensions ci-dessous.
Analyse en composantes principales (PCA) : Transformer les variables en composantes non corrélées.
Augmenter la taille de l'échantillon : Plus de données peuvent réduire les variances.
Hétéroscédasticité
L'hétéroscédasticité signifie que la variance des erreurs n'est pas constante :
Conséquences :
- L'estimateur OLS reste sans biais :
- Mais il n'est plus efficace (n'a plus la variance minimale)
- Les formules de variance sont incorrectes :
- Les intervalles de confiance et tests sont invalides
Détection :
Observation visuelle : Graphique résidus vs valeurs ajustées montre une forme d'entonnoir.
Test de Breusch-Pagan : Teste si la variance des erreurs dépend des variables explicatives.
Test de White : Version plus générale qui teste l'hétéroscédasticité sans hypothèse sur sa forme.
Solutions :
Transformation de la variable dépendante :
- Logarithme :
au lieu de (réduit l'impact des grandes valeurs) - Racine carrée :
- Logarithme :
Moindres carrés pondérés (WLS) : Voir section Extensions ci-dessous.
Erreurs-types robustes (estimateur sandwich) : Utiliser des estimateurs de variance robustes à l'hétéroscédasticité (Huber-White).
Points aberrants et points influents
Point aberrant (outlier) : Observation avec un résidu très élevé (écart important entre observation et prédiction).
Point influent (leverage point) : Observation qui a un impact important sur l'estimation des coefficients. Un point a un leverage élevé s'il est éloigné des autres observations dans l'espace des variables explicatives.
Distinction importante :
- Un point peut être aberrant sans être influent (hors du modèle mais dans une zone dense)
- Un point peut être influent sans être aberrant (dans le modèle mais dans une zone isolée)
- Les points les plus problématiques sont à la fois aberrants et influents
Mesures :
Résidus standardisés :
: Point aberrant
Leverage :
(élément diagonal de la matrice de projection) : Leverage élevé
Distance de Cook : Mesure combinée qui quantifie l'influence globale de l'observation
: : Point influent : Point très influent
Solutions :
Vérifier les données : Erreur de saisie, erreur de mesure ?
Examiner le contexte : Le point aberrant est-il légitime ou exceptionnel ?
Estimation robuste : Utiliser des méthodes robustes aux outliers (M-estimateurs, régression quantile).
Supprimer avec précaution : Ne supprimer que si justifié (après documentation).