Tutoriel : Régression polynomiale
Introduction
La régression polynomiale est une application directe du modèle linéaire présenté au Chapitre 2. L'objectif est d'approximer des données par un polynôme de degré fixé.
Problématique
Soit
Formulation en modèle linéaire
Construction de la matrice de design
Bien que nous cherchions un polynôme (non linéaire en
où :
est le vecteur des observations est le vecteur des coefficients du polynôme ( paramètres) est le bruit gaussien est la matrice de Vandermonde :
Remarque : Chaque ligne
Estimateur des moindres carrés
D'après le chapitre 2, l'estimateur du MLE (qui coïncide avec les moindres carrés) est :
Le polynôme ajusté est alors :
Exemple numérique
Données
Considérons
avec
Ajustement
Nous cherchons à estimer les coefficients avec un polynôme de degré
Matrice de design (premières lignes) :
Résultats : Le script Python ci-dessous génère les données et estime les coefficients.
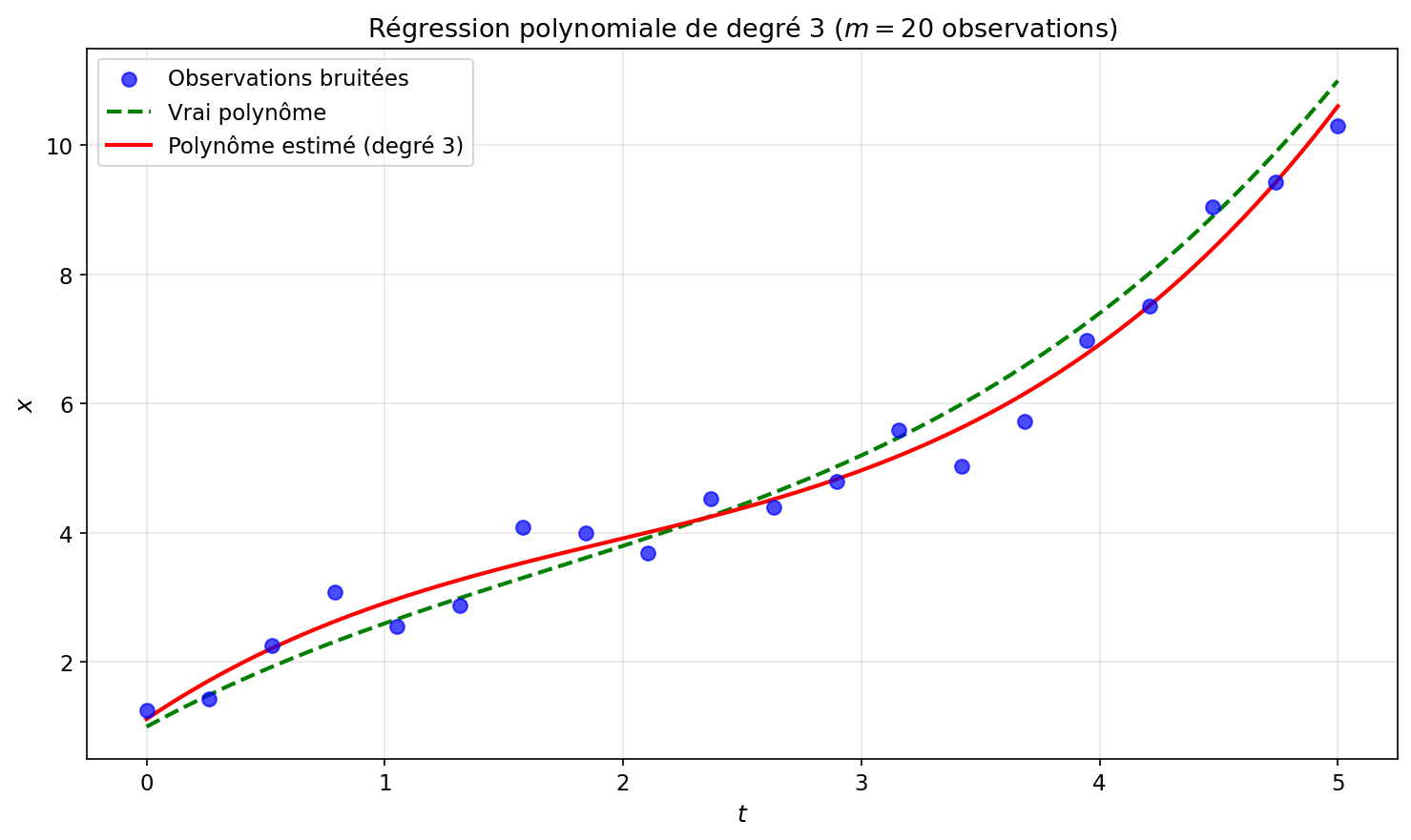
Figure 1: Ajustement polynomial de degré 3
Choix de l'ordre du polynôme
Sur-ajustement et sous-ajustement
- Sous-ajustement (
trop petit) : Le modèle est trop simple, l'erreur est élevée - Bon ajustement (
correct) : Le modèle capture la tendance des données - Sur-ajustement (
trop grand) : Le modèle colle trop aux données bruitées, mauvaise généralisation
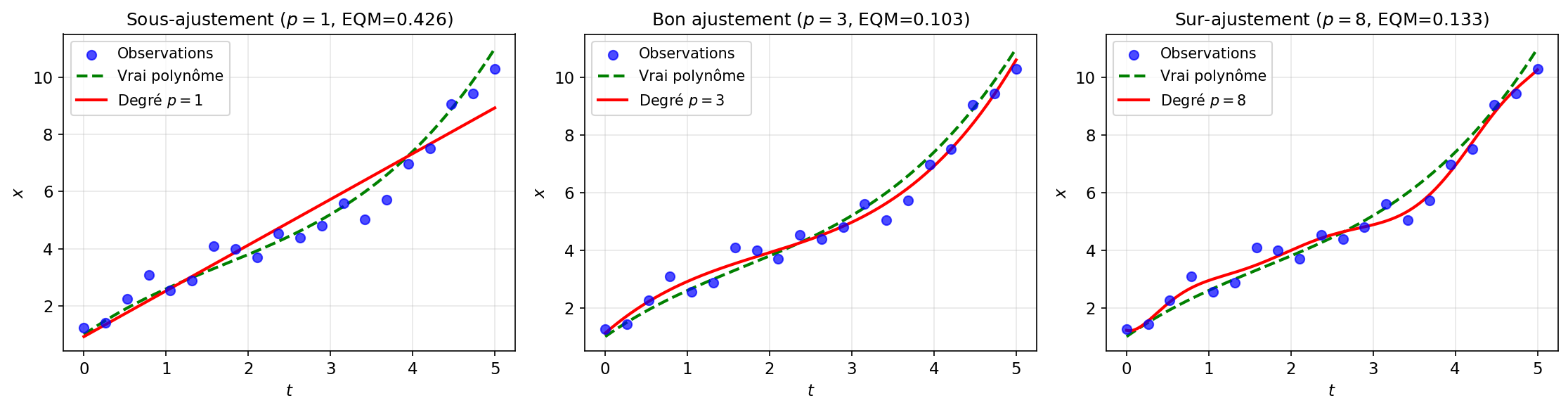
Figure 2: Comparaison de différents ordres de polynômes
Critère de sélection
Pour choisir
- Validation croisée : Séparer données d'entraînement/test
- Critères d'information : AIC, BIC qui pénalisent la complexité
Propriétés de l'estimateur
Biais et variance
- Biais :
(sans biais) - Matrice de covariance :
Remarque : La matrice
Intervalle de confiance
Pour chaque coefficient
Exercices
- Générer des données polynomiales de degré 2 et ajuster des polynômes de degrés 1, 2, 3, 5
- Comparer l'erreur quadratique moyenne pour chaque ordre
- Étudier l'effet du nombre d'observations
sur la qualité de l'estimation - Investiguer le conditionnement de
en fonction de
Code Python
Le script complet est disponible dans src/polynomial_regression.py.